
For a search engine, the first step is the data retrieval. It may come from diverse sources, and use many different formats.
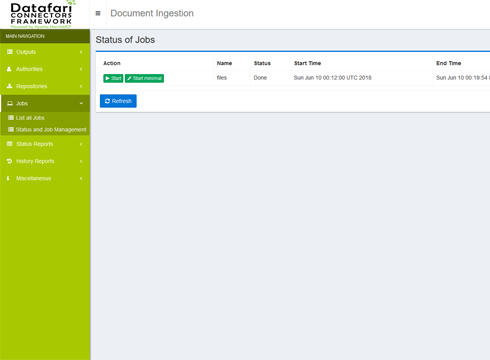
Administration
Our interface allows you to manage the connectors, and the connection to your LDAP/AD if necessary. It can also monitor the system status and the documents retrieval status.
Load management
Manage the load on your data sources, in terms of threads, retrieved documents, documents size. Time window management for the crawling.
Processing Filters
Possibility to create document processing filters, for instance with regular expressions to include or exclude documents or folders.
File Shares
Index your file shares(Netapp, windows, samba, Dropbox...), securely. Manage the OCR. Manage many formats (ppt, xls, html, jpeg, MS Office, open office...)
CMS and Portals
Index your CMS (Content Management System), ECM (Enterprise Content Management) or portals (Liferay, Alfresco, Sharepoint, Documentum, Filenet, CMIS...), securely.
All that's left
Databases, social networks, emails ... Plugin mechanism to develop new connectors. You can either create them by yourself, or rely on our know-how.

After crawling, it is the second step for a search engine. Once retrieved from the external sources, data must be indexed byt the search engine, and stored in a search index.
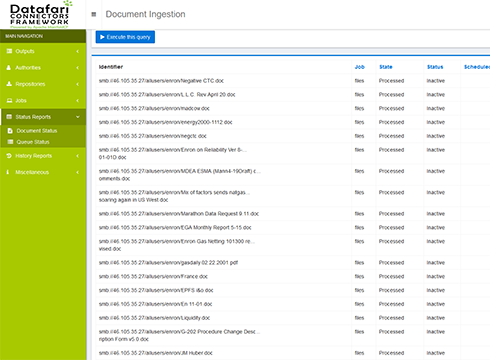
Scalability
Datafari is able to index hundreds of millions of documents, using a hadoop like big data architecture, on several machines.
Reliability
In distributed mode, the Zookeeper technology and Solrcloud allow for an automatic management of system failures.
Flexibility
Near realtime management, multi search field data types (int, string, date...), schema-less mode, possibility to add dynamic fields.
Once the crawling and indexing phases are over, it is the search engine that takes care of analysing search queries, and to find the most relevant documents
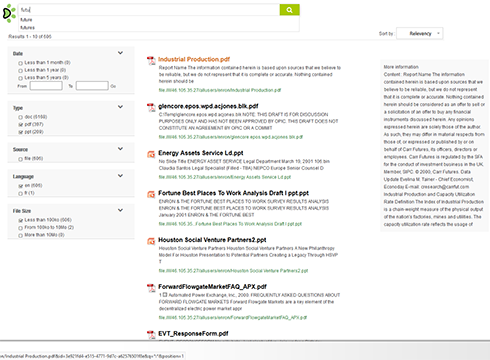
Big Data
The search engine can manage thousands of queries per second, using a hadoop like big data architecture, with several clustered machines.
Semantic
Multilingual, spellchecker, content suggestion, entity extraction (dates, places...), results clustering, ...
Flexible
The algorithm can be fully customised, for the algorithm itself as well as for the parameters used (real time boosts, fields selection, fuzzy search...).
Responsive Design
Our UI is responsive and adapts to the device. It is based on HTML and CSS and fully customisable.
Alerts
Users can save queries, and be informed via email that documents (new or modified) match their queries.
Smart Autocomplete
The autocomplete suggests queries to speed up the search process for the user.

In an organization, security is a key element for applications. For each phase of our enterprise search solution Datafari, security is there to guarantee data exchange confidentiality, and compliance with access rights.
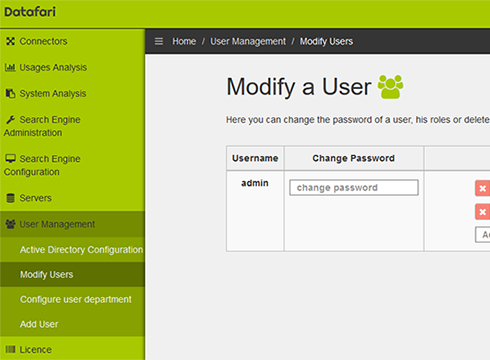
Authentication
Datafari can connect to the AD or LDAP in use, to authenticate users, but it can also manage users autonomously.
Authorization
Datafari connects to your systems managing authorisations and ACLs, in order to guarantee that users can only see what they are allowed to see.
Confidentiality
Activation of https for data exchanges between the different components of Datafari and the users, to ensure a strong encryption.
An enterprise solution must propose an administration tool that provides a fast ramp up. It is the case with Datafari.
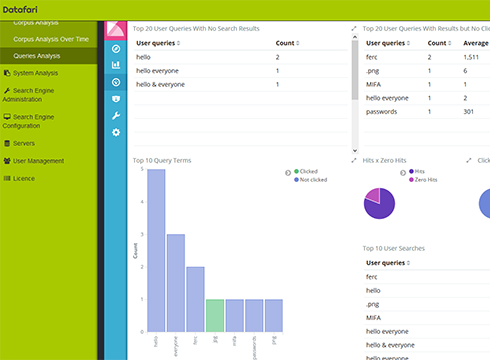
For The Administrator
Administration for alerts, servers, machines cluster, users, connection to AD/LDAP...
For The Search Expert
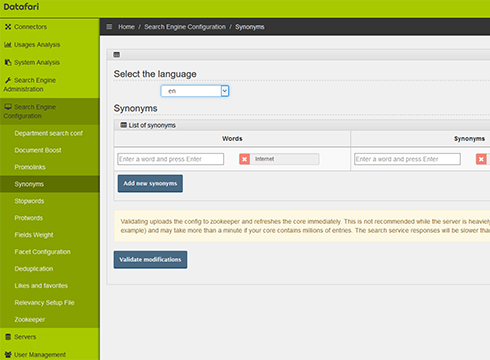
Administration for fields weights, promolinks, statistics, synonyms, stopwords, deduplication...
For The User
Administration for alerts, saved searches (when searches are complex), favorites (storing a result)...

Relevancy is a key element of an Enterprise Search Solution, especially because users do not come back when they are disappointed by the search results.
Algorithmic
Our algorithm can be tuned by giving a relative importance to the different components of the documents (content, metadata). But it can also boost specific documents for particular queries.
Semantic
Entity extraction and recognition (dates, authors, equipment numbers...) allows for better understanding of the documents, hence a better positioning in the ranking.
Contextual
We store the contextual information (user history, clicks, department...) and leverage it for user based relevancy computation. Our R&D in Machine Learning will even further optimise the relevancy through a neural network based reranking.
Used by various and renowned companies
